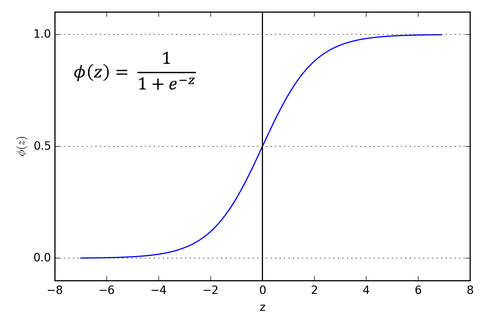
輸出介於0-1, 特別適用於概率輸出的模型
本身為單調函數(monotonic function)(漸增或漸減), 但導數不是
邏輯上,在訓練期間可能會卡住
一般會使用 softmax function 替代, 使得每一個元素都在0-1, 並且所有元素合為1
適用於多樣分類
 |
| 圖片來源 |
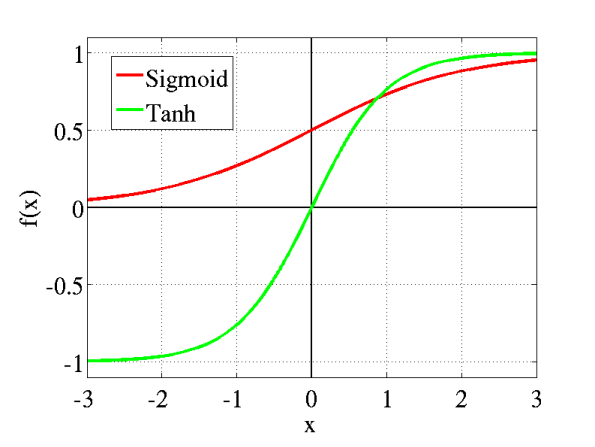
類似 sigmoid, 輸出介於 -1 到 1
本身為單調函數(monotonic function)(漸增或漸減), 但導數不是
適用於二分類
 |
| 圖片來源 |
為卷積神經網路或深度學習最常用的函數
輸出範圍從 0 到無限大
計算輛小,只需判斷輸入是否大於 0
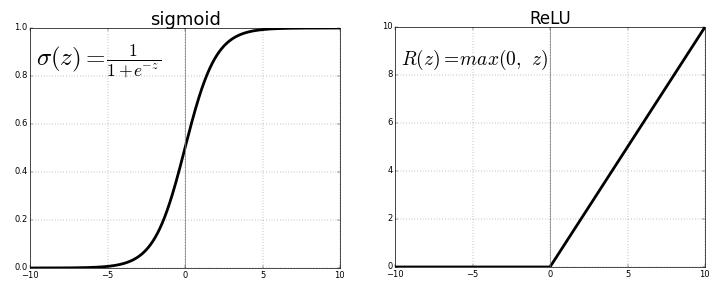 |
| 圖片來源 |
激勵函數一般建議使用ReLU, 或者變形的 Leaky ReLU, Tanh 和 Sigmoid 盡量別用,
因為他們有梯度消失的問題,是類神經網路加深時主要的訓練障礙。
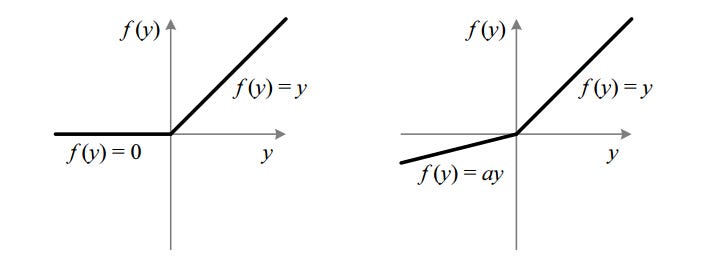 |
| 圖片來源 |
沒有留言:
張貼留言