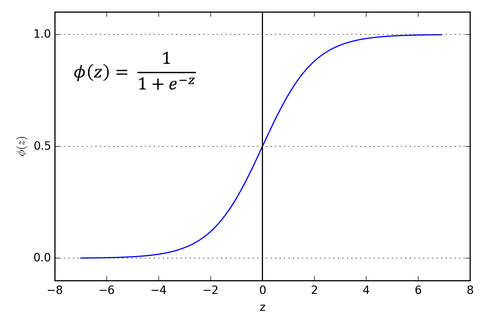
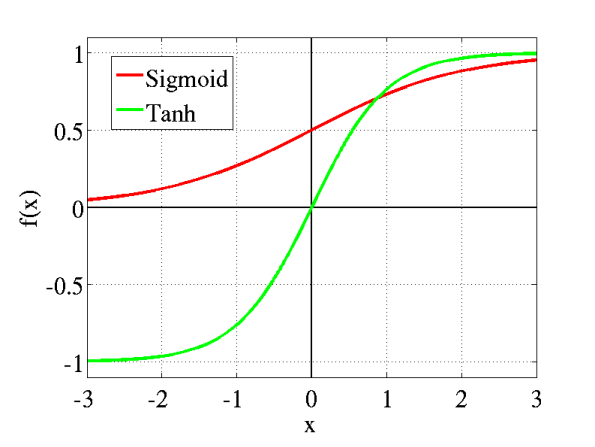
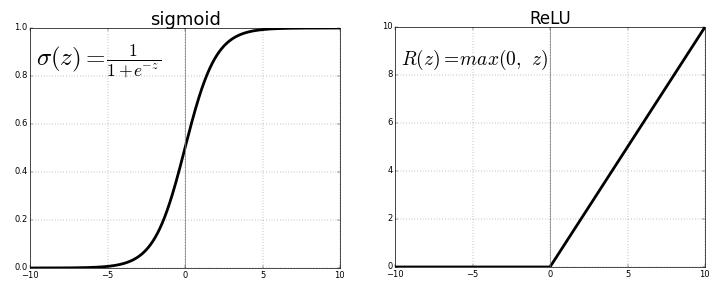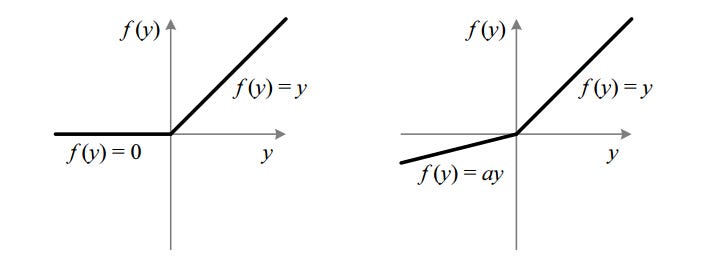Download object detection models from model zoo
set PATH=%PATH%;..\..\protoc-3.5.1-win32\bin
cd models-master\research
protoc.exe object_detection\protos\anchor_generator.proto --python_out=.
protoc.exe object_detection\protos\argmax_matcher.proto --python_out=.
.
.
.
protoc.exe object_detection\protos\train.proto --python_out=.
cd ..\..\
python setup.py build
python setup.py install
修改 models-master/research/object_detection/trainer.py
# Soft placement allows placing on CPU ops without GPU implementation.
session_config = tf.ConfigProto(allow_soft_placement=True,
log_device_placement=False)
session_config.gpu_options.allow_growth=True
session_config.gpu_options.allocator_type = "BFC"
session_config.gpu_options.per_process_gpu_memory_fraction = 0.4
LabelImg 標註相片,產生 .xml
修改 xml_to_csv.py 由 .xml 產生 .csv
修改 generate_tfrecord.py 內的 class_text_to_int(row_label), 標註從 1 開始,不是 0
由 .csv 產生 .record(TFRecord 檔)
準備 labelmap.pbtxt, 標註從 1 開始,不是 0
準備修改 models-master\research\object_detection\samples\configs